

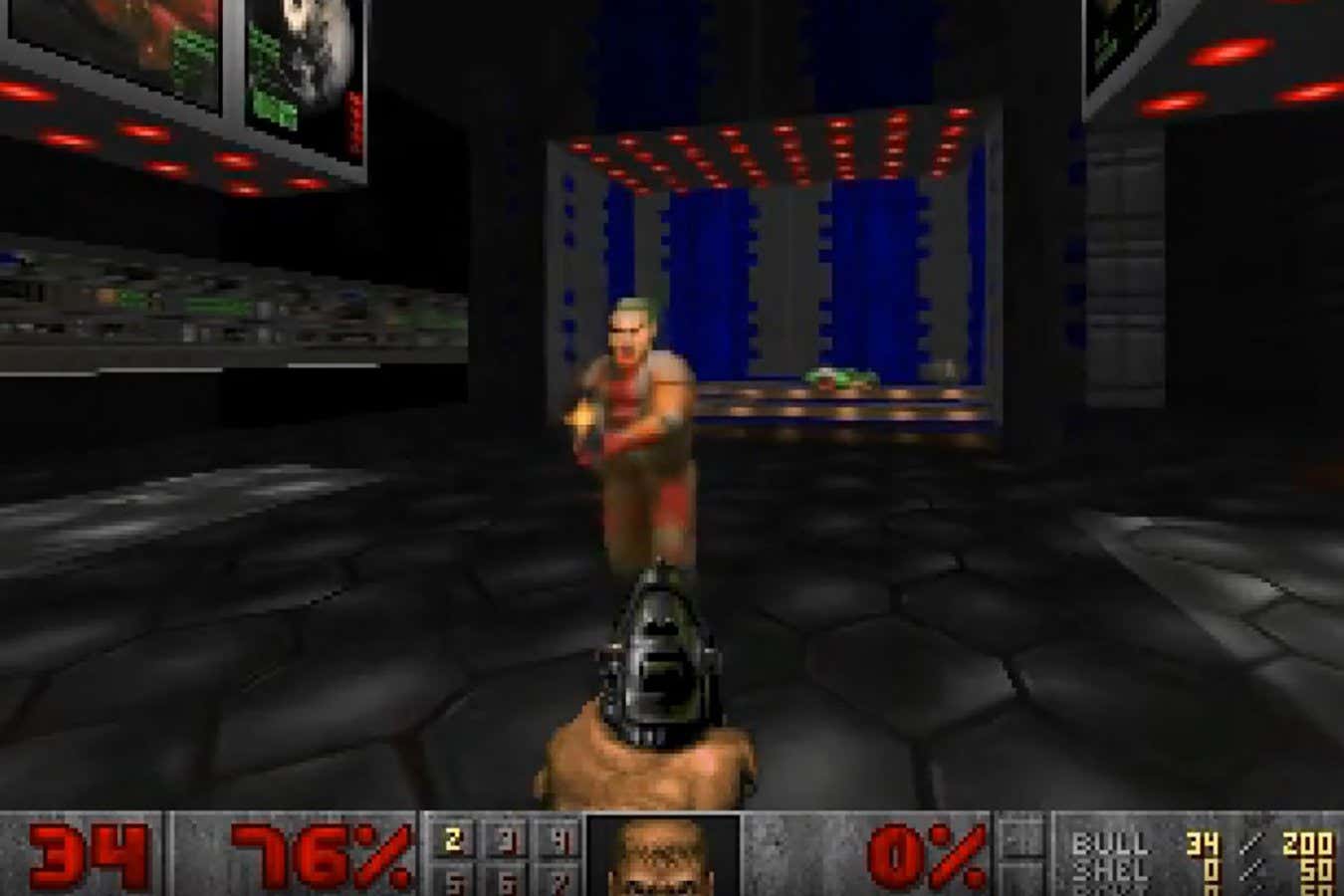
The model, called GameNGen, was made by Dani Valevski at Google Research and his colleagues, who declined to speak to New Scientist. According to their paper on the research, the AI can be played for up to 20 seconds while retaining all the features of the original, such as scores, ammunition levels and map layouts. Players can attack enemies, open doors and interact with the environment as usual.
After this period, the model begins to run out of memory and the illusion falls apart.
Why are we lying about this? Just because it happens in the AI “black box” doesn’t mean it’s not producing some kind of code in the background to make this work. They even admit that it “runs out of memory.” Huh, last I checked, you’d need to be running code to use memory. The AI itself is made of code! No computer code or graphics, my ass.
Always a good look. /s
I mean, yes, technically you build and run AI models using code. The point is there is no code defining the game logic or graphical rendering. It’s all statistical predictions of what should happen next in a game of doom by a neural network. The entirety of the game itself is learned weights within the model. Nobody coded any part of the actual game. No code was generated to run the game. It’s entirely represented within the model.
What they’ve done is flattened and encoded every aspect of the doom game into the model which lets you play a very limited amount just by traversing the latent space.
In a tiny and linear game like Doom that’s feasible… And a horrendous use of resources.
It doesn’t even actually do that. It’s a glitchy mess.
deleted by creator
Imagine you are shown what Doom looks like, are told what the player does, and then you draw the frames of what you think it should look like. While your brain is a computation device, you aren’t explicitly running a program. You are guessing what the drawings should look like based on previous games of Doom that you have watched.
Maybe they should have specified , the Doom Source Code
This would be like playing DnD where you see a painting and describe what you would do next as if you were the painting and they an artists painted the next scene for you.
The artists isn’t rolling dice, following the rule book, or any actual game elements they ate just painting based on the last painting and your description of the next.
Its incredibly nove approchl if not obviously a toy problem.
“No code” programming has been a thing for a while, long before the LLM boom. Of course all the “no code” platforms generate some kind of code based on rules provided by the user, not fundamentally different from an interpreter. This is consistent with that established terminology.
No code programming meant using a GUI to draw flowcharts that then creates running code. This is completely different.
Using a different high level interface to generate code is completely different? The fundamental concept is the same even if the UI is very different.
Yes it’s completely different. “No code” is actually all code just written graphically instead of with words. Every instruction that is turned into CPU instructions has to be drawn on a flowchart. If you want the “no code” to add A + B, you had to write A+B in a box on the flowchart. Have you taken a computer class? You must know what a flowchart is.
This Doom was done by having a neural net watch Doom being played. It then recreates the images from Doom based on what it “learned”. It doesn’t have any code for “mouse click -> call fire shotgun function” Instead it saw that when someone clicked the mouse, pixels on the screen changed in a particular way so it simulates the same pixel pattern it learned.