

2·
15 days agoAhh, I see lol
Web Dev Person / Ex Performance ECU Calibrations Person
Ahh, I see lol
I’m not sure I understand at all?
It’s fully open source, can run/connect any number of fully local models as well as the big name models if a user chooses to use them.
Can you expand on what you mean?
Thanks!
Unfortunately currently there isn’t a true RAG implementation largely due to the fact that this site/app is fully self contained with no additional servers or database etc…which is typically required for RAG.
For now file uploads are stored in the browser’s own local database and the content can be extracted and added to the current conversation context easily.
I definitely want to add a more full RAG system but it’s a process to say the least, and if I implement it I want it to be quite effective. My experience with RAG generally has left me quite unimpressed with a few quite decent implementations being the exception.
Web search is definitely something I want to add, haven’t quite figured out the route I want to take implementing it just yet though.
Hopefully I can get it added sooner rather than later!

This project is entirely web based using Vue 3, it doesn’t use langchain and I haven’t looked into it before honestly but I do see they offer a JS library I could utilize. I’ll definitely be looking into that!
As a result there is no LLM function calling currently and apps like LM Studio don’t support function calling when hosting models locally from what I remember. It’s definitely on my list to add the ability to retrieve outside data like searching the web and generating a response with the results etc…
Yep that’s a pretty good comparison!
I’m curious on what you mean by sourcing training data in an ethical way? I know OpenAI has come under well deserved scrutiny for apparently using content that is hidden behind paywalls without purchasing it themselves in their training data. Which is quite unethical, but aside from that instance I’m interested in hearing some other concerns for my own education.
In general there are definitely loads of models on places like Hugging Face that are fully open source and provide training data sources for many.
I believe for Microsoft’s new Phi 3 models they actually generated synthetic data themselves for training as well which is an interesting approach that seems to yield good results.
In the open source LLM world the new Meta Llama 3 models are the latest and greatest, I haven’t seen any cause for concerns with it yet. Might be worth looking into those!
I haven’t personally tried it yet with Ollama but it should work since it looks like Ollama has the ability to use OpenAI Response Formatted API https://github.com/ollama/ollama/blob/main/docs/openai.md
I might give it go here in a bit to test and confirm.
Local models are indeed already supported! In fact any API (local or otherwise) that uses the OpenAI response format (which is the standard) will work.
So you can use something like LM Studio to host a model locally and connect to it via the local API it spins up.
If you want to get crazy…fully local browser models are also supported in Chrome and Edge currently. It will download the selected model fully and load it into the WebGPU of your browser and let you chat. It’s more experimental and takes actual hardware power since you’re fully hosting a model in your browser itself. As seen below.
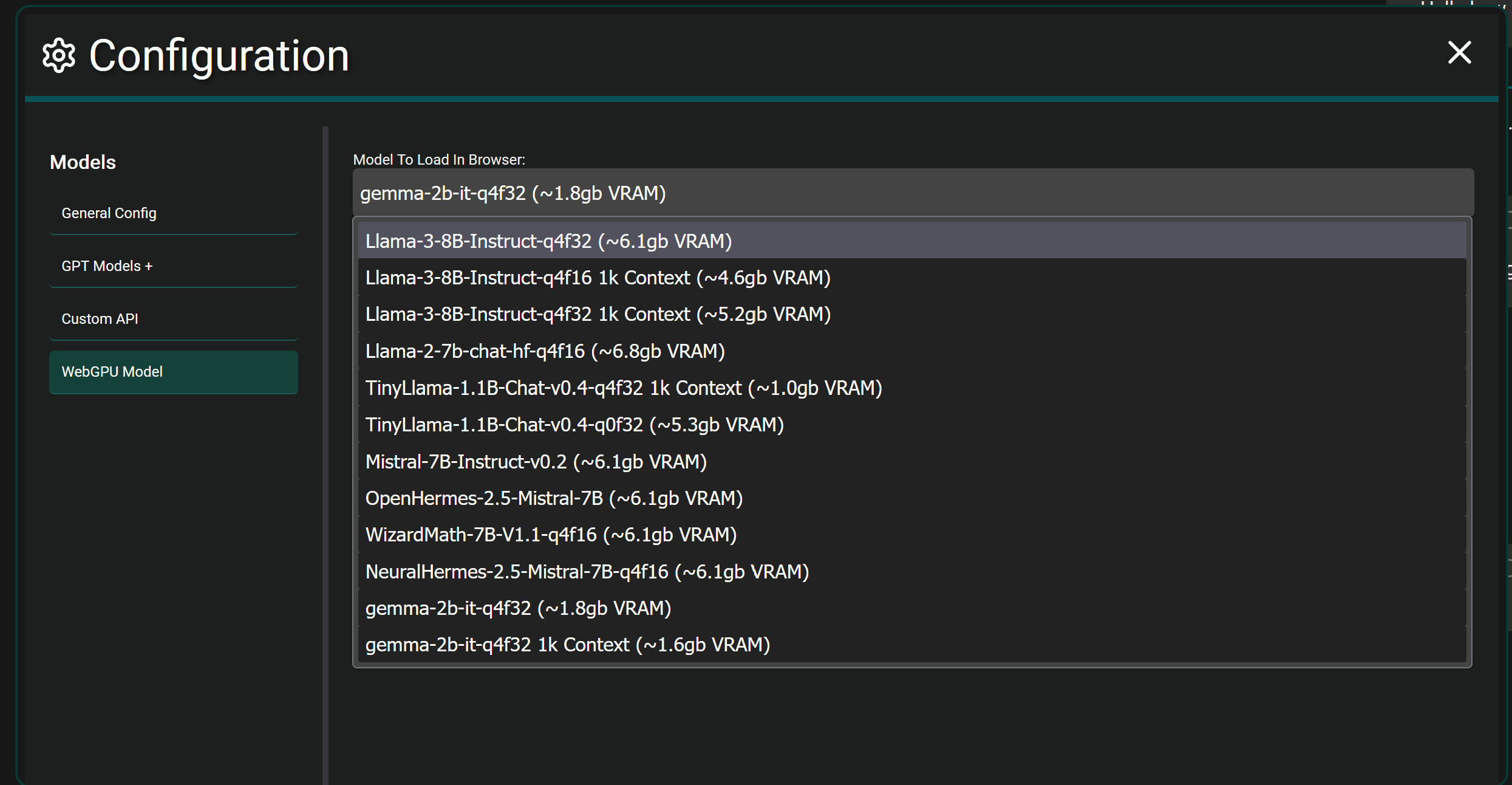
This app is more of an interface to use while connecting to any number of LLM Models that have an API available. The application itself has no model.
For example you can choose to use GPT-4 Omni by providing an API key from OpenAI.
But you can also connect to services like OpenRouter with an API key and select between 20+ different models that they provide access to as seen below
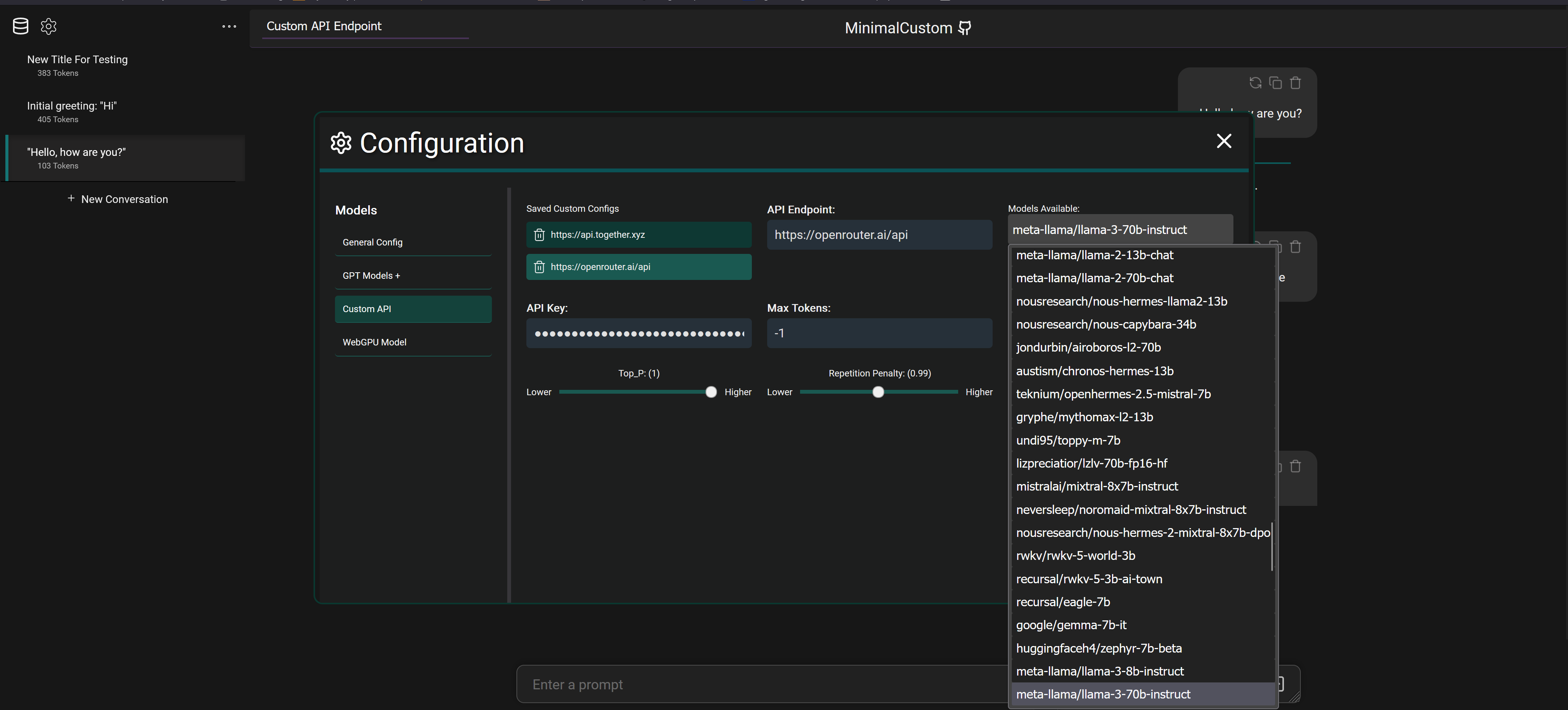
It also supports connecting to fully local models via programs like LM Studio which downloads models from Hugging Face to your machine and will spin up a local API to connect and chat with the model.

Removed by mod
What are you talking about? You are the one who ranted about people proving you wrong.
You made a big deal out of someone being perfectly pleasant replying to you.
Your viewpoint of anyone responding to you with anything other than agreement as an attack seems to be the real issue.
I’m not upset, you shouldn’t be either, it’s not that big of a deal.
Removed by mod
Seems like a friendly enough response was given to your comment and you automatically assumed they were only interested in saying you’re wrong.
Having a discussion is not “proving everyone wrong”
You’ve never actually used them properly then.


That seems like a pretty naive and biased approach to software to me honestly.
Ease of use, community support, feature set, CI/CD etc…all should come into play when deciding what to use.
Freedom at all costs is great until you limit the community development and potential user base by 90% by using a completely open repo service that 5% of the population uses or some small discord alternative.
So then the option is to host on multiple platforms/communities and the management and time investment goes up keeping them in sync and active.
As with most things in life, it’s best to look at things with nuance rather than a hard stance imo.
I may stand it up on another service at some point, but also anyone else is totally free to do that as well. There are no restrictions.